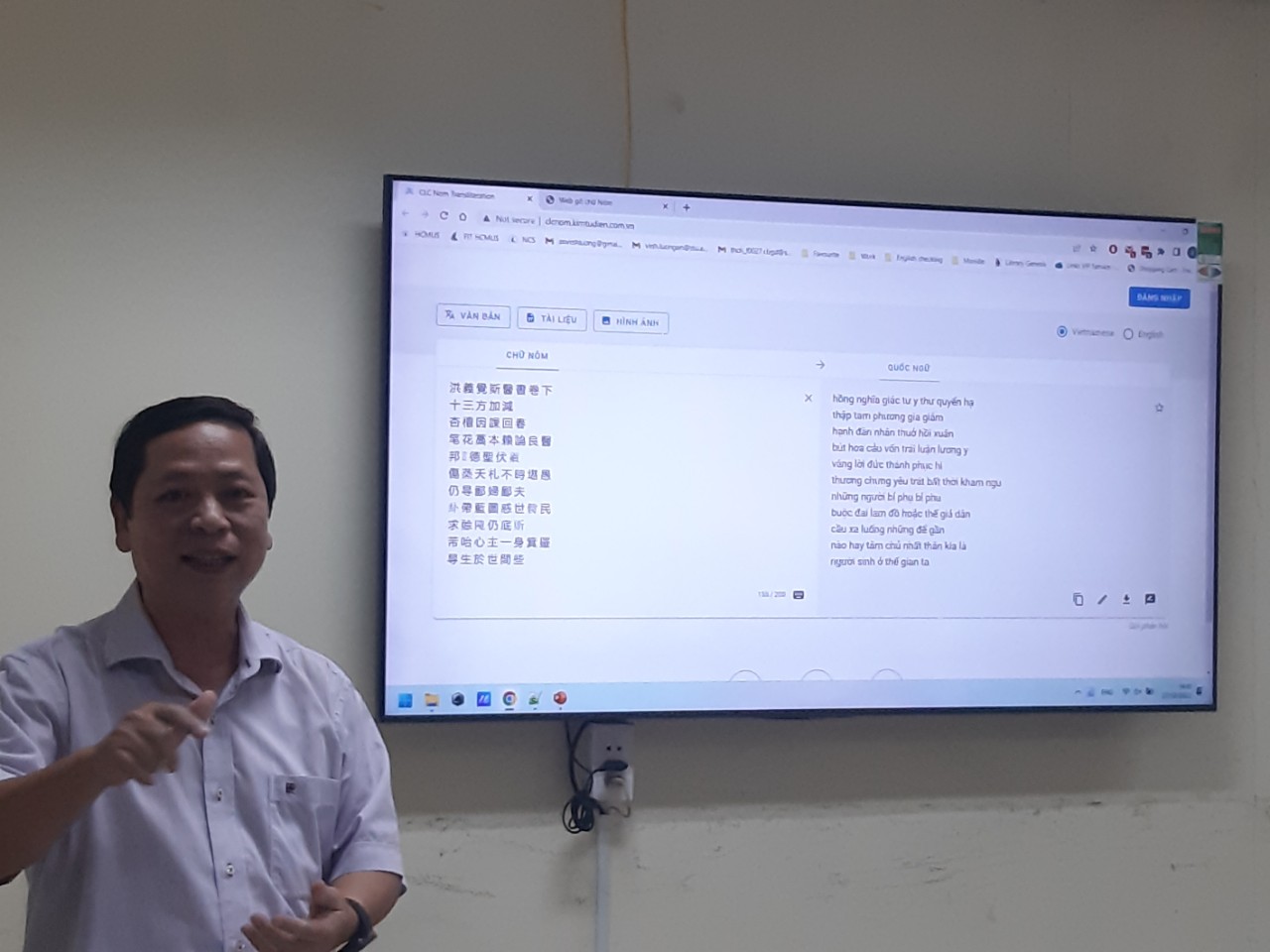
Hệ thống chuyển tự chữ Nôm đã được đưa lên website của trường ĐH Khoa học Tự nhiên - ĐH Quốc gia TPHCM nhằm phục vụ nhu cầu tra cứu của mọi người.

PGS.TS Đinh Điền thuyết minh và vận hành thị phạm tính năng chuyển tự tự động văn bản chữ Nôm sang văn bản chữ Quốc ngữ tại Hội đồng tư vấn nghiệm thu nhiệm vụ khoa học – công nghệ do Sở KH&CN TPHCM tổ chức. Ảnh: Hcmfosted
Chữ Nôm là loại văn tự ngữ tố - âm tiết dùng để viết tiếng Việt. Đây là bộ chữ được người Việt tạo ra dựa trên chữ Hán, các bộ thủ, âm đọc và nghĩa từ vựng trong tiếng Việt.
Trong suốt mười thế kỷ hình thành và phát triển (từ thế kỷ 10 đến thế kỷ 20), đã có nhiều công trình về lịch sử, văn học, y học, nông nghiệp, địa lý, … được viết bằng chữ Nôm; tuy nhiên phần lớn số công trình vẫn chưa được dịch (chuyển tự) sang chữ Quốc ngữ (chữ viết hệ Latin). Trong khi đó, hiện tại có rất ít người có khả năng đọc được chữ Nôm để tìm hiểu, khai thác tài liệu trong quá khứ. Với mong muốn xây dựng hệ thống có khả năng dịch tự động chữ Nôm sang chữ Quốc ngữ, PGS.TS Đinh Điền (Trường ĐH Khoa học Tự nhiên – ĐH Quốc gia TPHCM) đã cùng các đồng nghiệp triển khai nhiệm vụ khoa học – công nghệ “Xây dựng hệ thống chuyển tự tự động văn bản chữ Nôm sang chữ Quốc ngữ”.
Việc chuyển tự ở đây là sự thay thế chữ viết từ dạng này sang dạng khác trong cùng một ngôn ngữ. Ví dụ: chuyển tự từ hệ chữ Cyrillic của tiếng Nga sang hệ chữ Latin, như: “Путин” thành “Putin”, hay từ hệ chữ Hangeul của tiếng Hàn sang hệ chữ Latin, như: “삼성” thành “Samsung”. Việc chuyển tự này rất đơn giản vì có sự tương ứng (gần như) 1-1 giữa một mẫu tự trong hệ chữ Cyrillic hay Hangeul với một mẫu tự tương ứng trong hệ chữ Latin. Do cả ba hệ chữ viết trên cùng thuộc loại hình chữ viết ghi âm vị (alphabet) nên việc chuyển tự hoàn toàn được thực hiện một cách tự động, nhanh chóng và chính xác bằng cách tra bảng (ánh xạ).
Tuy nhiên, việc chuyển tự từ chữ Nôm sang chữ Quốc ngữ, ngược lại, vô cùng phức tạp do hai hệ chữ không cùng thuộc một loại hình chữ viết. Chữ Nôm thuộc loại hình chữ viết ghi ý (ideographic) còn chữ Quốc ngữ thuộc loại hình chữ viết ghi âm vị theo cách phân chia 6 loại hình chữ viết trên thế giới trong công trình của Rogers H. Do đó, chúng ta không thể áp dụng cách tra bảng (ánh xạ) vì không có sự tương ứng 1-1 giữa một chữ Nôm với một chữ Quốc ngữ như trong ví dụ chữ tiếng Nga hay tiếng Hàn nói trên.
“Việc chuyển tự tự động từ chữ Nôm sang chữ Quốc ngữ là bài toán rất khó vì chính con người chúng ta khi đọc chữ Nôm cũng phải ‘vừa đọc vừa đoán’ vì cùng một chữ Nôm có thể được “dịch” (chuyển tự) sang nhiều chữ Quốc ngữ khác nhau”, PGS. Điền giải thích.
Một chữ Nôm gồm thường gồm hai phần: phần ghi âm và phần ghi ý. Chẳng hạn, chữ 蹎 (“chân” trong “chân tay”): chữ này được cấu thành từ chữ “túc” 足 (ghi ý) và chữ “chân” 真 (ghi âm). Việc suy đoán này phải dùng đến nhiều tri thức cả trong và ngoài ngôn ngữ (extra-linguistic) như văn hóa, lịch sử, địa lý, tiếng Việt cổ, tiếng địa phương, từ chuyên ngành, v.v.
Nhờ sự phát triển vượt bậc của lĩnh vực AI cũng như các công nghệ học máy trong những năm gần đây, máy tính hiện có thể tự “học” được cách chọn (“suy đoán”) chữ Quốc ngữ phù hợp với từng chữ Nôm thông qua ngữ cảnh trong rất nhiều các bản dịch Nôm – Quốc ngữ trước đó của con người. Bằng cách cung cấp cho máy càng nhiều bản dịch Nôm – Quốc ngữ chuẩn, máy sẽ càng “thông minh” hơn và cho kết quả dịch chính xác hơn. Ngoài ra, máy cũng có khả năng tự học để hoàn thiện hơn bằng cách rút kinh nghiệm từ các lỗi dịch sai của máy sau khi con người hiệu đính lại những chỗ dịch sai đó. Được biết, kho ngữ liệu đơn ngữ chữ Quốc ngữ được nhóm nghiên cứu “nạp dạy” cho hệ thống hiện ở mức hơn 823 nghìn câu và hơn 13 triệu từ.
Để nâng cao chất lượng, các nhà khoa học đã tập trung dịch một chiều từ chữ Nôm sang chữ Quốc ngữ. Việc dịch một chiều từ chữ Nôm sang chữ Quốc ngữ sẽ giúp dễ tập trung cải tiến chất lượng đầu ra của chữ Quốc ngữ hơn bằng cách đầu tư nhiều cho mô hình ngôn ngữ (Language Model) của chữ Quốc ngữ. Cụ thể, nhóm đã xây dựng Tự điển chữ Nôm – Quốc ngữ (bản chất là một tập hợp có hệ thống các Nôm tự được giải nghĩa Quốc ngữ) nhằm tập trung giải nghĩa của từng tự, cung cấp các thông tin sâu về mặt ngôn ngữ học. (“Tự” là đơn vị nhỏ nhất trong quá trình xử lý ngữ liệu để chuẩn bị cho quá trình chuyển tự. Cấp độ lớn hơn “tự” là từ và cụm từ.)
Ngoài ra, PGS.TS Đinh Điền và cộng sự đã xây dựng ngữ liệu cho lĩnh vực văn học, đời sống và tôn giáo. "Nếu chúng ta huấn luyện cho máy tính hiểu được/biết được ngữ liệu thuộc thể loại, lĩnh vực nào thì máy sẽ dịch tốt hơn với những văn bản thuộc thể loại hay lĩnh vực đó", nhóm cho hay.
Sau một thời gian dài phát triển, vào tháng 4 vừa qua, Trường ĐH Khoa học Tự nhiên và nhóm nghiên cứu đã đưa hệ thống chuyển tự chữ Nôm nói trên lên website chính thức của trường (https://tools.clc.hcmus.edu.vn/) nhằm phục vụ nhu cầu tra cứu của mọi người.
Về cơ bản, phần mềm giao diện website chuyển tự tự động chữ Nôm sang chữ Quốc ngữ đi kèm bộ gõ chữ Nôm tích hợp, cho phép người dùng chọn lĩnh vực (văn học, lịch sử, tôn giáo) và thể loại (văn xuôi, văn vần) của ngữ liệu đầu vào. Các kết quả thực nghiệm bản dịch văn bản chữ Nôm sang chữ Quốc ngữ với bản dịch chữ Quốc ngữ (bản gốc) được đánh giá là chuẩn xác ở mức cao.
Cũng theo lời nhóm phát triển, giải pháp dịch văn bản chữ đã hoàn thành, hiện nay, nhóm đang tiếp tục phát triển thêm khối (module) nhận dạng văn bản ảnh (bằng cách chụp hình chữ Nôm thay vì phải gõ vào hay dán vào) hay còn gọi là OCR (Optical Character Recognization). Khối nhận dạng này sẽ được tích hợp vào hệ thống chuyển tự hiện nay để qua đó du khách có thể dịch nội dung của các tài liệu, hình ảnh (liễn, câu đối, bia) được viết bằng chữ Nôm thường thấy ở các khu di tích, đền đài,… chỉ bằng camera của điện thoại di động.
Theo khoahocphattrien